关于/About
研究/Research
出版/Publication
成员/Members
联系/Contact
出版 / Publications
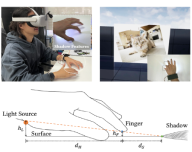
ShadowTouch: Enabling Free-Form Touch-Based Hand-to-Surface Interaction with Wrist-Mounted Illuminant by Shadow Projection
Chen Liang, Xutong Wang, Zisu Li, Chi Hsia, Mingming Fan, Chun Yu, and Yuanchun Shi
UIST 2023
Exploring the Opportunities of AR for Enriching Storytelling with Family Photos
Zisu Li, Li Feng, Chen Liang, Yuru Huang, Mingming Fan
IMWUT 2023
Understanding In Situ Programming for Smart Home Automation
Xiaoyi Liu, Yingtian Shi, Chun Yu, Cheng Gao, Tianao Yang, Chen Liang, Yuanchun Shi
IMWUT 2023
From 2D to 3D: Facilitating Single-Finger Mid-Air Typing on Virtual Keyboards
Xin Yi, Chen Liang, Haozhan Chen, Jiuxu Song, Chun Yu, Hewu Li, Yuanchun Shi
IMWUT 2023
Enabling Voice-Accompanying Hand-to-Face Gesture Recognition with Cross-Device Sensing (Honorable Mention Award)
Zisu Li, Chen Liang, Yuntao Wang, Yue Qin, Chun Yu, Yukang Yan, Mingming Fan, Yuanchun Shi
ChI 2023
Selecting Real-World Objects via User-Perspective Phone Occlusion
Yue Qin, Chun Yu, Wentao Yao, Jiachen Yao, Chen Liang, Yueting Weng, Yukang Yan, Yuanchun Shi
CHI 2023
DRG-Keyboard: Enabling Subtle Gesture Typing on the Fingertip with Dual IMU Rings
Chen Liang, Chi Hsia, Chun Yu, Yukang Yan, Yuntao Wang, Yuanchun Shi
IMWUT 2022
DualRing: Enabling Subtle and Expressive Hand Interaction with Dual IMU Rings
Chen Liang, Chun Yu, Yue Qin, Yuntao Wang, Yuanchun Shi
IMWUT 2021
Auth+Track: Enabling Authentication-Free Interaction on Smartphone by Continuous User Tracking
Chen Liang, Chun Yu, Xiaoying Wei, Xuhai Xu, Yongquan Hu, Yuntao Wang, Yuanchun Shi
CHI 2021
HandSee: Enabling Full Hand Interaction on Smartphones with Front Camera-based Stereo Vision
Yu Chun, Xiaoying Wei, Shubh Vachher, Yue Qin, Chen Liang, Yueting Weng, Yizheng Gu, Yuanchun Shi
CHI 2019
DeepChannel: Salience Estimation by Contrastive Learning for Extractive Document Summarization
Jiaxin Shi, Chen Liang, Lei Hou, Juanzi Li, Zhiyuan Liu, Hanwang Zhang
AAAI 2019